我们为该 Demo 录制了一期讲解视频:📺 bilibili。
什么是DeepResearch
Deep Research(也称为 Agentic Deep Research)是指大语言模型(LLM)协同工具(如搜索、浏览器、代码执行、记忆存储等),以“多轮推理→检索→验证→融合”的闭环方式,完成复杂任务的研究型智能代理。 不同于单次检索的 RAG(Retrieval-Augmented Generation),Deep Research 更像人的专家思路——先制定计划,再不断探索、调整方向、核实信息,最终输出结构完整、有出处的报告。前置准备
在本次开发中,我们将基于 UltraRAG 框架 完成示例。考虑到大多数小伙伴可能没有算力服务器,我们全程在一台 MacBook Air (M2) 上实现,确保环境轻量、易于复现。API准备
- 检索 API:我们采用 Tavily Web Search,初次注册即可免费获得 1000 次调用额度。
- LLM API:你可以根据自己的习惯选择任意大模型服务。本教程中,我们使用 gpt-5-nano 作为示例
API设置
我们提供了两种方式传入 API Key:环境变量和显式参数。其中推荐使用 环境变量,更安全,也能避免 API Key 在日志中泄漏。 在 UltraRAG 根目录下,将模板文件.env.dev 重命名为 .env,
并填写你的密钥信息,例如:
Pipeline介绍
在本示例中,我们将实现一个轻量级的 Deep Research Pipeline。它具备以下基本功能:- Plan 制定:模型先根据用户问题制定解决方案的计划;
- 子问题生成与检索:将大问题分解为可检索的子问题,并调用 Web 搜索工具获取相关资料;
- 报告整理与填充:逐步完善研究报告的内容;
- 推理与最终生成:在报告完成后,模型给出最终答案。
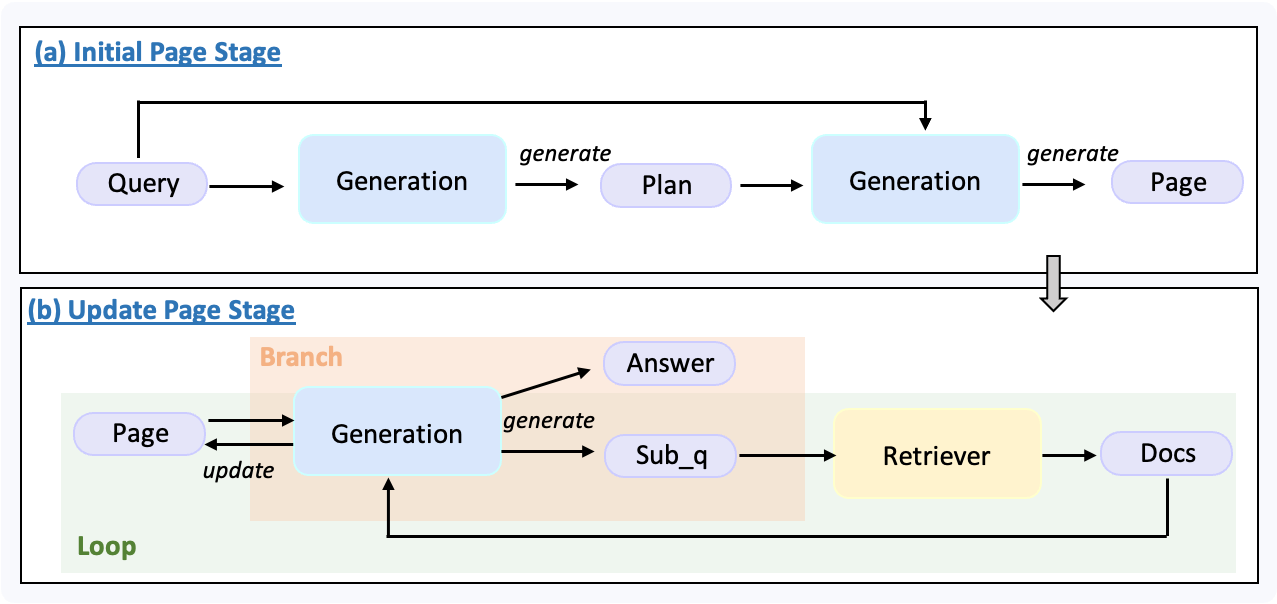
- 初始化阶段: 模型会根据用户问题生成一份 plan,并据此构造出初始的报告 page。
- 迭代填充阶段:
- 系统会检查当前报告 page 是否已填充完整。
- 判断标准为:page 中是否仍存在 “to be filled” 字符串。
- 如果报告尚未完成,模型会结合用户问题、plan 与当前 page,生成一个新的子问题并触发 Web 检索。
- 检索到的文档会被用于更新 page,然后进入下一轮检查。
- 这个过程会持续迭代,直到 page 被填满。
examples/webnote_websearch.yaml

运行
构建问题数据
首先,在 data 文件夹下新建一个名为 sample_light_ds.jsonl 的文件,并写入你要研究的问题。例如:data/sample_light_ds.jsonl

构建参数配置文件
执行以下命令生成 pipeline 对应的参数文件:examples/parameter/webnote_websearch_parameter.yaml
启动
在运行前,不要忘记设置你的 API Key: