我们为该 Demo 录制了一期讲解视频:📺 bilibili。
什么是RAG?
想象你在参加一次开卷考试。你本人就是大语言模型,具备理解题目和写答案的能力。RAG(Retrieval-Augmented Generation,检索增强生成)是一种让大语言模型(LLM)在“生成”之前,先去“检索”相关文档或知识库,再结合这些信息生成回答的技术。
但你不可能记住所有知识点。这时,允许你带一本教材或参考书进考场——这就是检索。
当你翻书找到相关内容,再结合自己的理解去写答案,这样答案既准确又有根据。
这就是 RAG —— 检索增强生成。
流程
检索阶段:根据用户问题,从文档库中找到最相关的内容(比如知识库、网页等);\

作用
- 提升准确度、降低“幻觉”
- 无需重训模型,也能保持时效性和专业性
- 增强可信度
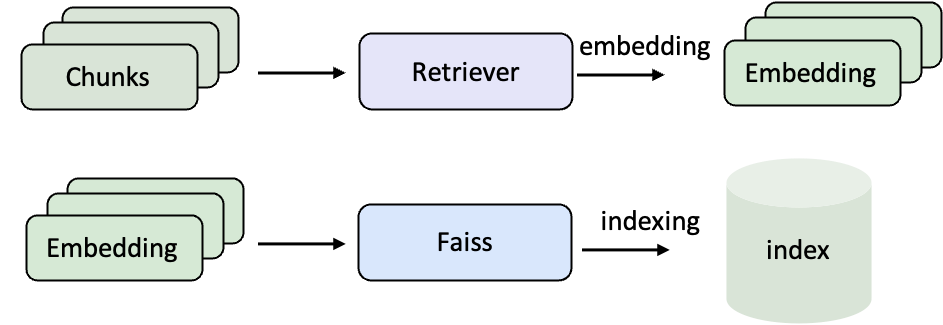
语料库编码与索引
在使用 RAG 之前,需要先将原始文档转化为 向量表示,并建立 检索索引。这样,当用户提问时,系统才能在大规模语料库中快速找到最相关的内容。- 编码(Embedding):把自然语言文本转化为向量,让计算机可以用数学方式比较语义相似度。
- 索引(Indexing):把这些向量组织起来,比如用 FAISS,这样检索时才能在几百万条文档中瞬间找到最相关的若干条。
示例语料(Wiki 文本)
data/corpus_example.jsonl

编写编码、索引Pipeline
examples/corpus_index.yaml

编译Pipeline文件
修改参数文件
examples/parameters/corpus_index_parameter.yaml
运行Pipeline文件
screen 或 nohup 将任务挂载至后台运行,例如:
搭建RAG Pipeline
当语料库的索引准备完成后,下一步就是将 检索器 和 大语言模型(LLM) 组合起来,搭建一个完整的 RAG Pipeline。这样,问题可以经过检索找到相关文档,再交由模型生成最终回答。检索流程
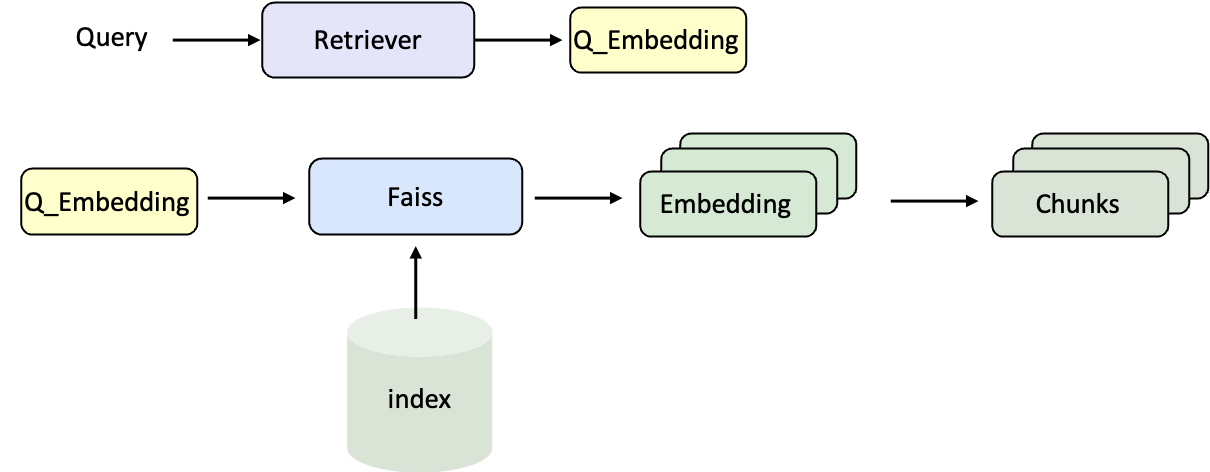
生成流程
数据格式(以 NQ 数据集为例)
data/sample_nq_10.jsonl
编写RAG Pipeline
examples/rag.yaml
- 读取数据 → 2. 初始化检索器并搜索 → 3. 启动 LLM 服务 → 4. 拼接 Prompt → 5. 生成回答 → 6. 提取结果 → 7. 评测性能。
编译 Pipeline 文件
修改参数文件(指定数据集、模型与检索配置)
examples/parameters/rag_parameter.yaml