论文:https://arxiv.org/abs/2502.17888RankCoT 包含两个阶段:先用“知识精炼模型”对检索文档进行提炼,再用“答案生成模型”基于提炼结果作答。两者本质都是 LLM 推理,因此在 UR-2.0 中可通过 Server 别名复用同一套 Generation Server 代码,只在 Pipeline 中为其取不同别名并配置不同参数/模型即可(详见 Server 别名复用机制)。
Step 1: 明确工作流结构
我们先来回顾论文提出的 RankCoT原始流程结构图: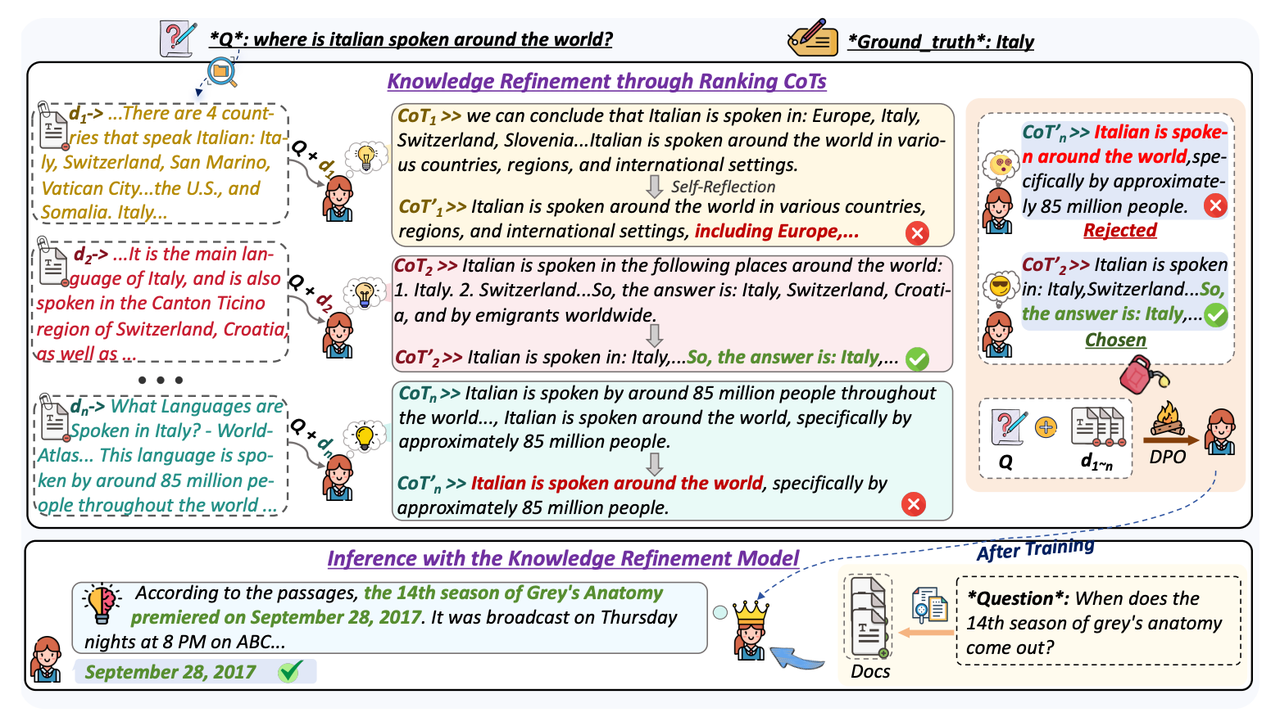

Step 2:实现必要Tool
RankCoT知识精炼部分先基于检索回来的外部知识和问题生成一条推理链,为此在servers/prompt/src/prompt.py 中添加如下代码:
servers/prompt/src/prompt.py
servers/prompt/src/prompt.py 中添加如下代码:
servers/prompt/src/prompt.py
Step 3:编写 Pipeline 配置文件
在examples/ 目录下新建一个 YAML 文件,如 RankCoT.yaml:
 examples/RankCoT.yaml
examples/RankCoT.yamlservers/generation 别名为 cot 与 gen,并在 Pipeline 中分别调用。
Step 4:配置 Pipeline参数
执行下列命令:examples/parameter/RankCoT_parameter.yaml,为两个别名分别指定不同的模型或推理参数:
examples/parameter/RankCoT_parameter.yamlcot 与 gen 各自拥有独立参数区块,互不覆盖。