- 编写 Pipeline 配置文件
- 编译 Pipeline 并调整参数
- 运行 Pipeline
Step 1:编写 Pipeline 配置文件
请确保当前工作目录位于 UltraRAG 根目录下
examples文件夹中创建并编写你的 Pipeline 配置文件,例如:
examples/rag_full.yaml

servers:声明当前流程所依赖的各个模块(Server)。例如,检索阶段需要使用retrieverServer。pipeline:定义各 Server 中功能函数(Tool)的调用顺序。本示例展示了从数据加载、检索编码与索引构建,到生成与评测的完整流程。
Step 2:编译 Pipeline 并调整参数
在运行代码前,首先需要配置运行所需的参数。UltraRAG 提供了快捷的 build 指令,可自动生成当前 Pipeline 所依赖的完整参数文件。 系统会读取各个 Server 的 parameter.yaml 文件,解析本次流程中涉及的全部参数项,并统一汇总生成到一个独立的配置文件中。执行以下命令: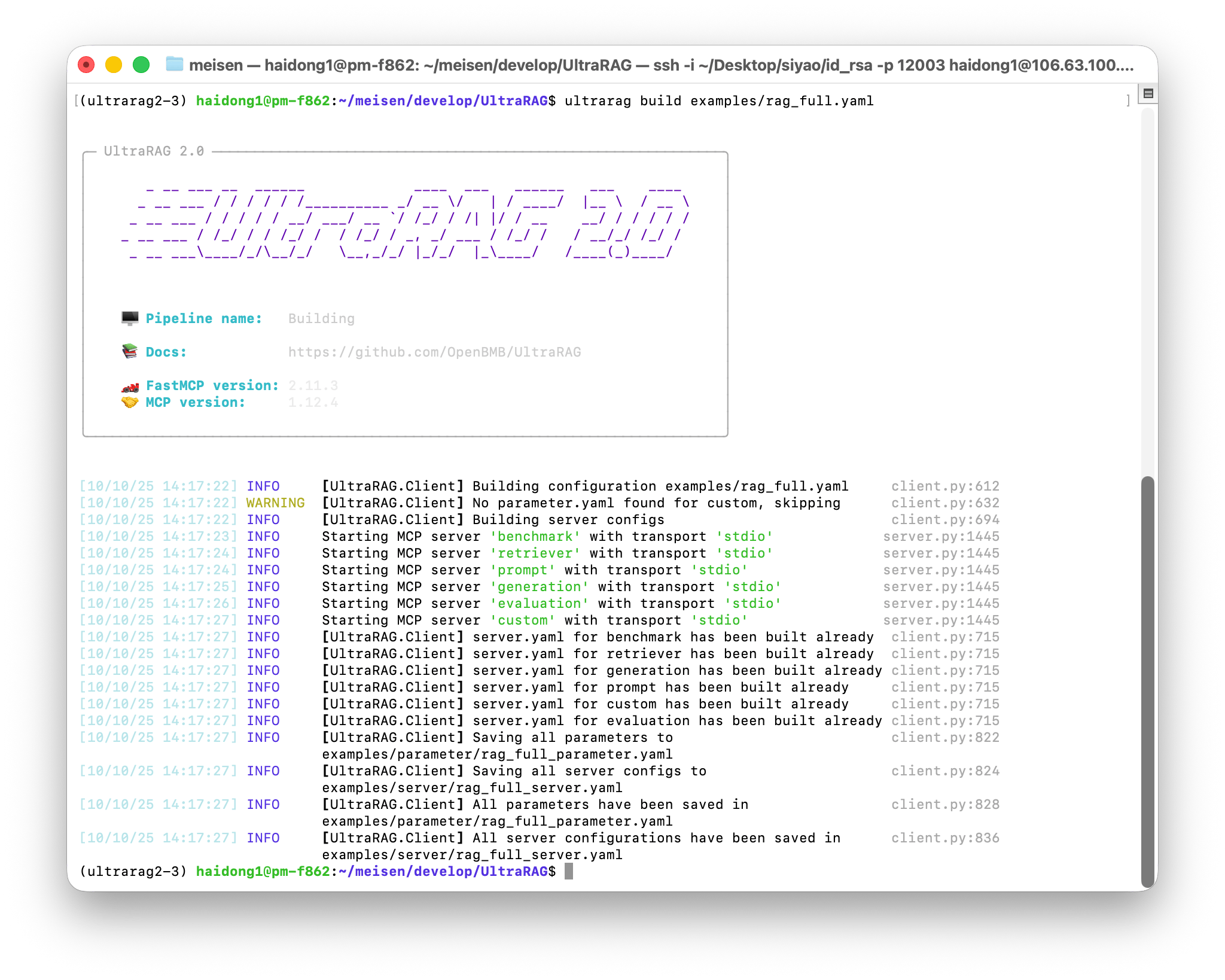
examples/parameters/文件夹下生成对应的参数配置文件。打开文件后,可根据实际情况修改相关参数,例如:
examples/parameters/rag_full_parameter.yaml
- 将 template 调整为RAG模版 prompt/qa_rag_boxed.jinja;
- 替换检索器与生成器的 model_name_or_path 为本地下载的模型路径;
- 若在多 GPU 环境下运行,可修改 gpu_ids 以匹配可用设备。
Step 3:运行 Pipeline
当参数配置完成后,即可一键运行完整流程。执行以下命令: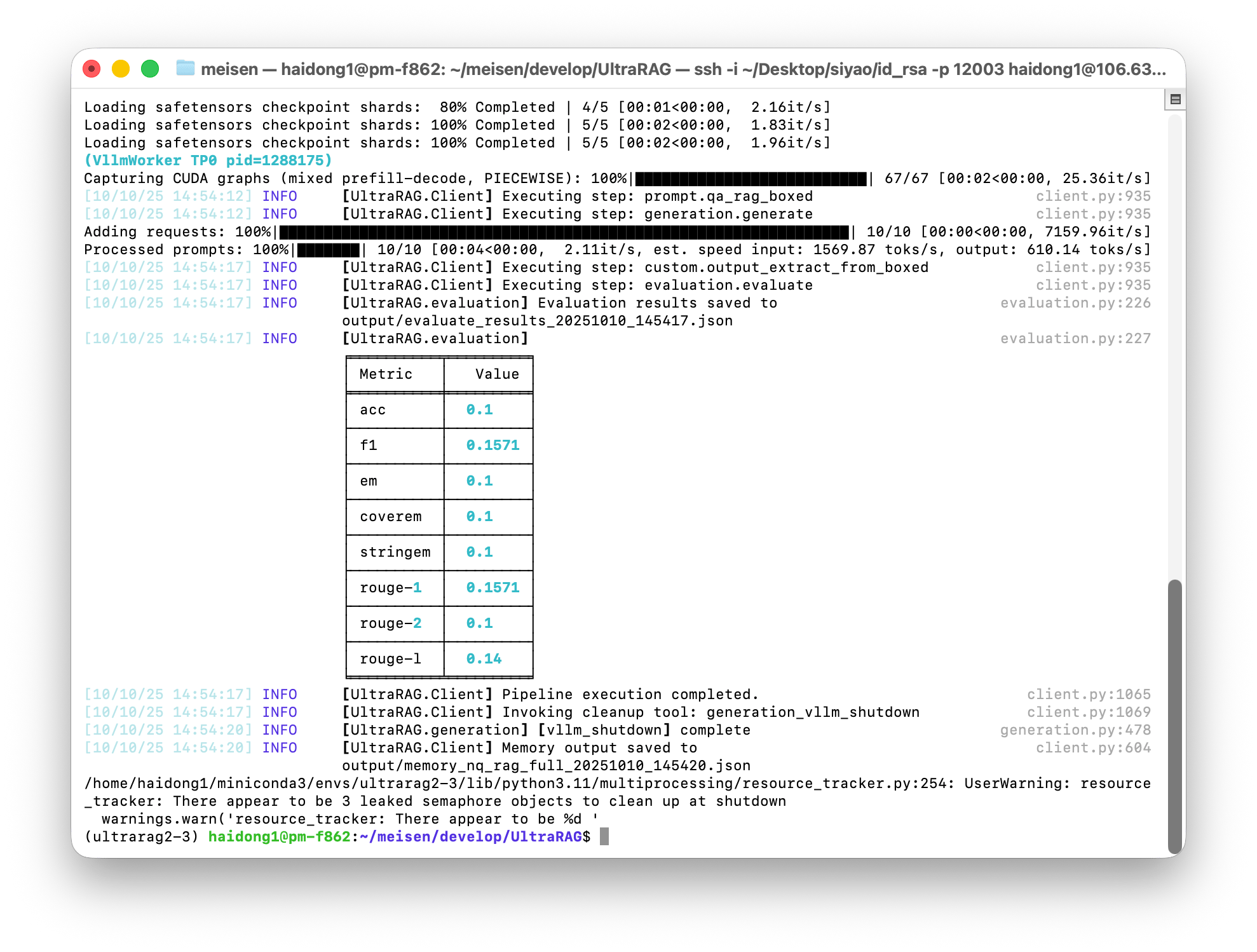
output/memory_nq_rag_full_20251010_145420.json可直接用于后续分析与可视化展示。
Step 4:可视化分析 Case Study
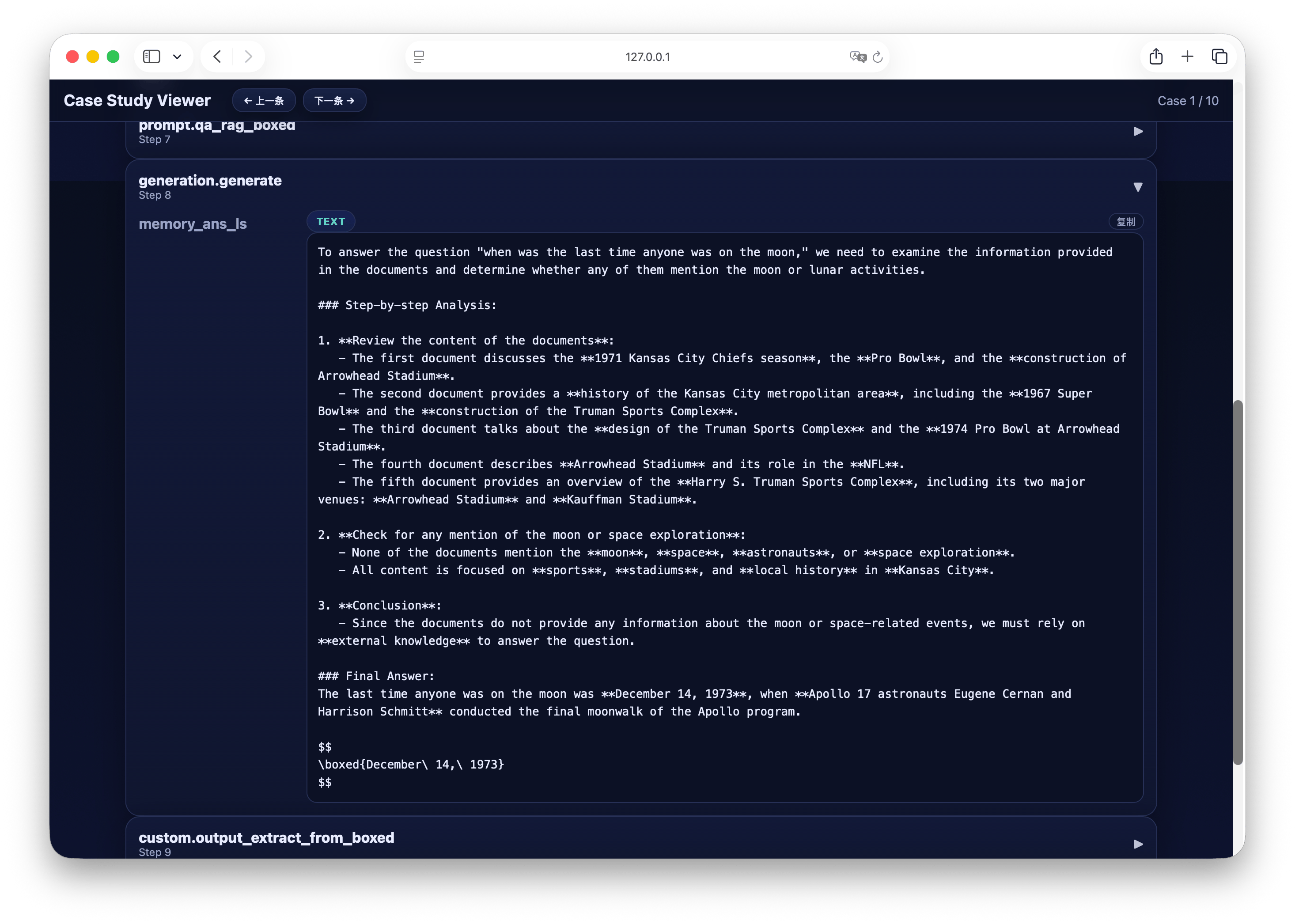
完成流程运行后,可通过内置的可视化工具快速分析生成结果。执行以下命令启动 Case Study Viewer: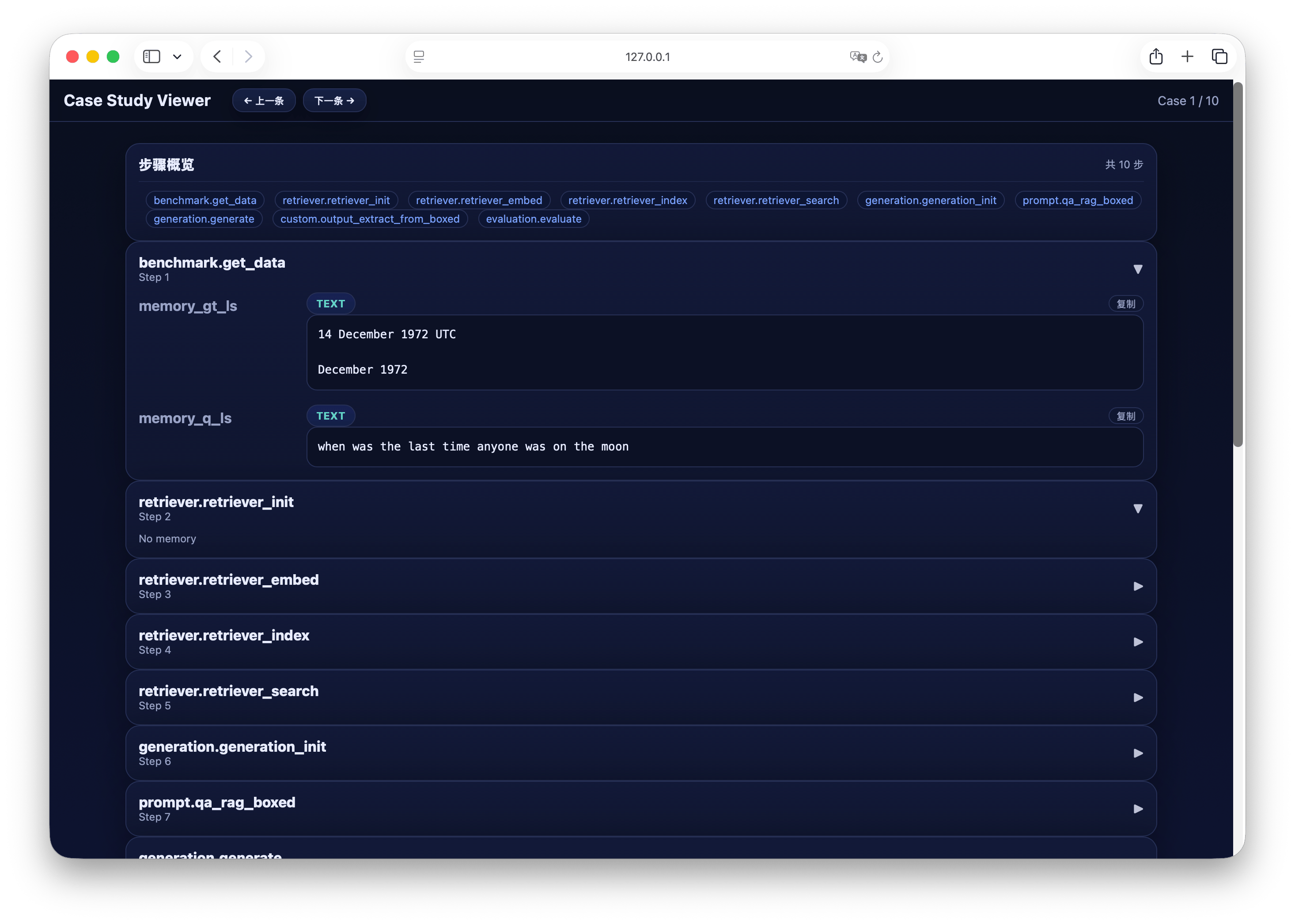
小结
至此,你已完成从 Pipeline 配置、参数编译 到 流程运行与可视化分析 的完整 RAG 实践流程。 UltraRAG 通过模块化的 MCP 架构与统一的评测体系,使得 RAG 系统的构建、运行与分析更加高效、直观、可复现。 你可以在此基础上:- 替换不同的模型或检索器,探索多种组合效果;
- 自定义新的 Server 与 Tool,扩展系统功能;
- 利用评测模块快速对比实验结果,开展系统性研究。