UltraRAG
UltraRAG is the first lightweight RAG development framework designed based on the Model Context Protocol (MCP) architecture, specifically built for research exploration and industrial prototyping. It standardizes core RAG components (such as Retriever, Generation, etc.) into independent MCP Servers, enabling flexible extension based on function-level Tool interfaces. Leveraging the process scheduling capabilities of the MCP Client, developers can achieve precise orchestration of complex control structures (such as conditions, loops, etc.) through YAML configuration. Furthermore, the system supports seamless migration of algorithmic logic to conversational demo interfaces, greatly optimizing the full-link efficiency of complex RAG system development.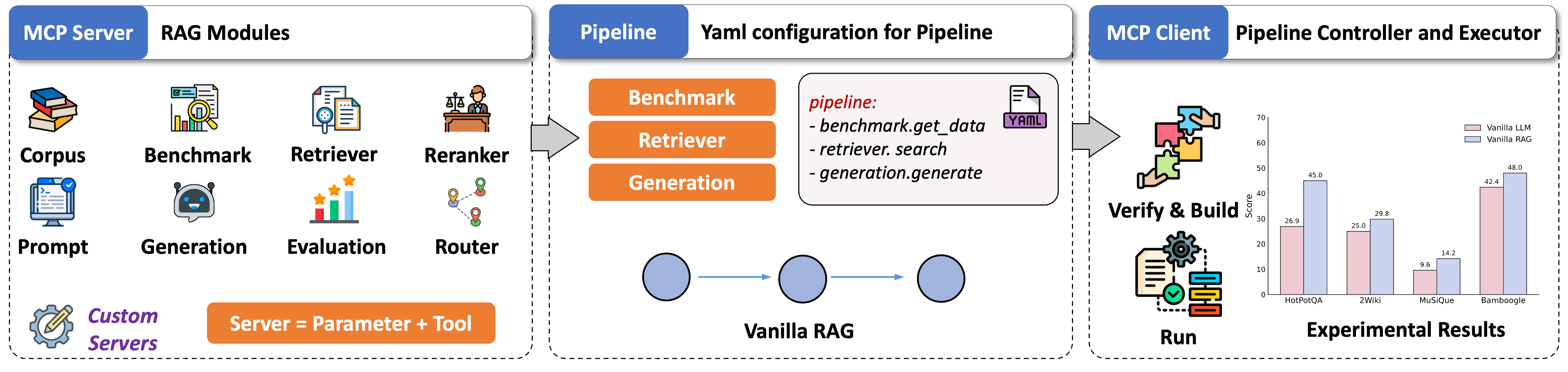
📑 Pipeline · Process Definition
Core Blueprint: Task logic written by users via YAML, defining the execution order and business logic of each component, realizing configurable inference processes.
🕹️ Client · Scheduling Hub
Command Center: Responsible for parsing Pipeline configurations, unifying the coordination of tool calls and data transfer between Servers, ensuring precise process execution.
⚙️ Server · Functional Execution
Capability Carrier: Standardizes core functions into independent services, supporting rapid extension and flexible combination of new modules through simple interfaces.
🖥️ UI · Interactive Demo
Visual Portal: Instantly converts logic defined in YAML into an intuitive conversational Web UI with a single command, significantly improving system debugging efficiency and demonstration effects.
Why UltraRAG?
RAG systems are undergoing a paradigm shift from static chain concatenation to autonomous reasoning systems, increasingly relying on the model’s active reasoning, dynamic retrieval, and conditional decision-making. However, traditional frameworks often face bottlenecks such as lack of flexibility, deep module coupling, and loose structures when dealing with multi-turn interactions and dynamic updates, making it difficult for researchers to efficiently reproduce and horizontally compare results. UltraRAG aims to break this deadlock by providing developers with a standardized, decoupled, and minimalist new development paradigm:🚀 Low-Code Orchestration of Complex Processes
Inference Orchestration: Natively supports control structures such as serial, loop, and conditional branching. Developers only need to write a YAML configuration file to implement complex iterative RAG logic within dozens of lines of code.
⚡ Modular Extension and Reproduction
Atomic Servers: Decouples functions into independent Servers based on the MCP architecture. New functions only need to be registered as function-level Tools to seamlessly integrate into the process, achieving extremely high reusability.
📊 Unified Evaluation and Benchmark Comparison
Research Efficiency: Built-in standardized evaluation processes, ready-to-use mainstream scientific research Benchmarks. Through unified metric management and baseline integration, the reproducibility of experiments and comparison efficiency are significantly improved.
✨ Rapid Prototyping of Interactions
One-Click Delivery: Say goodbye to tedious UI development. With just one command, Pipeline logic can be instantly converted into an interactable conversational Web UI, shortening the distance from algorithm to demonstration.