We recorded an explanatory video for this Demo: 📺 bilibili.
What is RAG?
Imagine you are taking an open-book exam. You are the large language model yourself, capable of understanding questions and writing answers. But you can’t remember all the knowledge points. At this time, you are allowed to bring a textbook or reference book into the exam room — this is retrieval. When you find relevant content in the book, and then combine it with your own understanding to write the answer, the answer is both accurate and grounded. This is RAG — Retrieval-Augmented Generation.RAG (Retrieval-Augmented Generation) is a technology that allows Large Language Models (LLMs) to “retrieve” relevant documents or knowledge bases before “generating” answers, and then combine this information to generate responses.
Process
Retrieval Phase: Find the most relevant content from the document library (such as knowledge bases, web pages, etc.) based on user questions;

Benefits
- Improve accuracy and reduce “hallucinations”
- Maintain timeliness and professionalism without retraining the model
- Enhance credibility
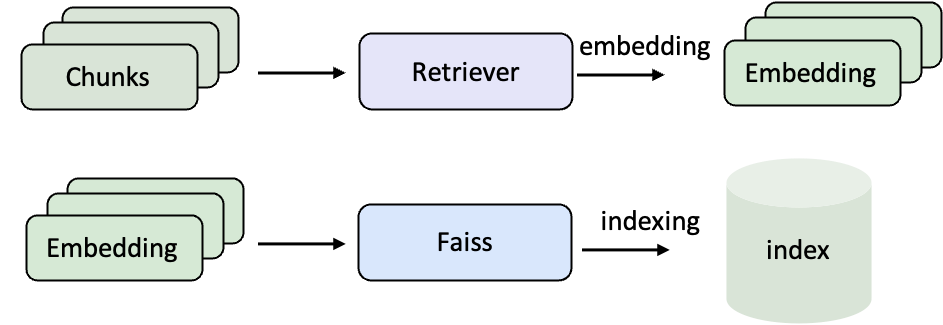
Corpus Encoding and Indexing
Before using RAG, original documents need to be converted into vector representations and a retrieval index needs to be established. In this way, when a user asks a question, the system can quickly find the most relevant content in the large-scale corpus.- Embedding: Convert natural language text into vectors so that computers can compare semantic similarities mathematically.
- Indexing: Organize these vectors, for example using FAISS, so that retrieval can instantly find the most relevant entries among millions of documents.
Example Corpus (Wiki Text)
data/corpus_example.jsonl

id is the unique identifier of the document, and contents is the actual text content. We will vectorize contents and build an index later.
Write Encoding and Indexing Pipeline
examples/corpus_index.yaml

Compile Pipeline File
Modify Parameter File
examples/parameters/corpus_index_parameter.yaml
Run Pipeline File
screen or nohup to mount the task to run in the background, for example:
Build RAG Pipeline
After the corpus index is ready, the next step is to combine the Retriever and the Large Language Model (LLM) to build a complete RAG Pipeline. In this way, questions can be retrieved to find relevant documents, and then handed over to the model to generate the final answer.Retrieval Process
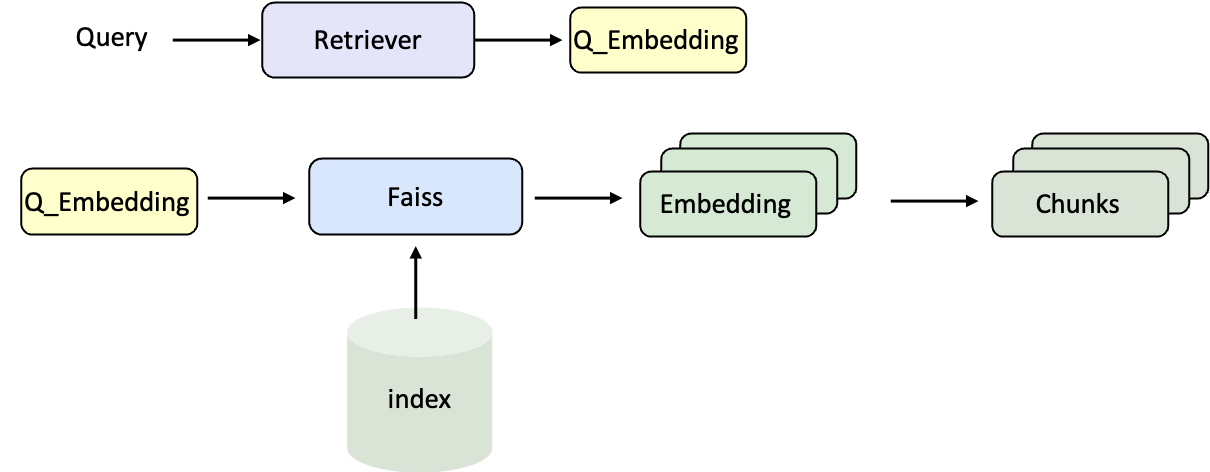
Generation Process
Data Format (Taking NQ Dataset as Example)
data/sample_nq_10.jsonl
golden_answers), and additional information (meta_data), which will be used as input and evaluation benchmarks later.
Write RAG Pipeline
examples/rag.yaml
- Read data → 2. Initialize retriever and search → 3. Start LLM service → 4. Assemble Prompt → 5. Generate answer → 6. Extract result → 7. Evaluate performance.
Compile Pipeline File
Modify Parameter File (Specify Dataset, Model, and Retrieval Configuration)
examples/parameters/rag_parameter.yaml