Introduction
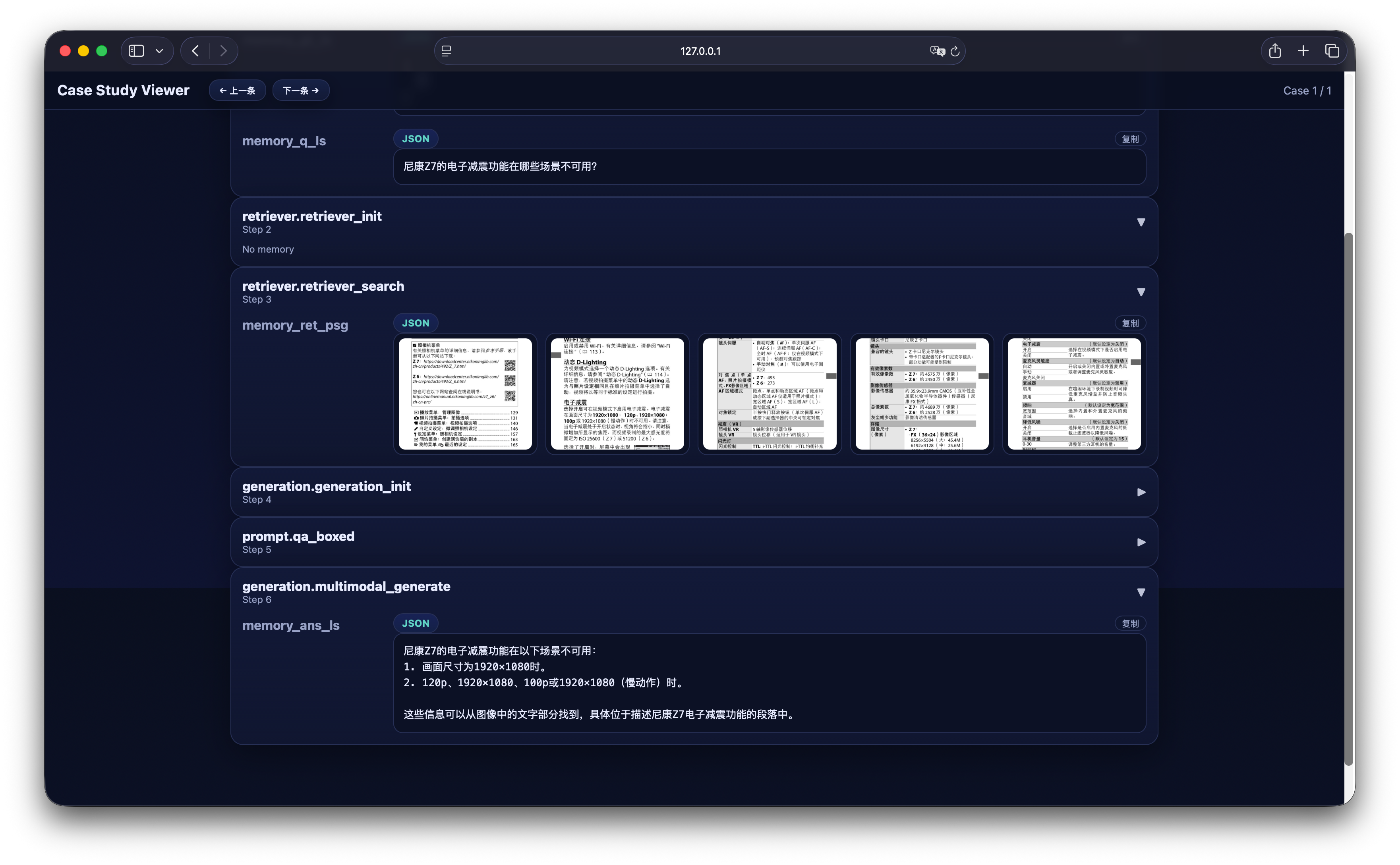
In daily use, we often encounter scenarios like this: buying a new device but not knowing how to set up certain functions, and flipping through the manual is both time-consuming and inefficient. At this time, if there is an intelligent assistant that can directly answer questions, it will greatly improve the experience. For example, a user purchased a Nikon Z7 camera and wants to know “in which scenarios the electronic vibration reduction function is unavailable”. Asking LLM directly yields the following answer:Build Personal Knowledge Base
Take “Nikon User Manual” as an example. You can click here to download the PDF file. We use UltraRAG’s Corpus Server to convert this PDF directly into an image corpus:examples/build_image_corpus.yaml

examples/parameters/build_image_corpus_parameter.yaml
corpora/image.jsonl

examples/corpus_index.yaml
examples/parameters/corpus_index_parameter.yaml
VisRAG
Prepare user query file:data/test.jsonl
examples/visrag.yaml
examples/parameters/visrag_parameter.yaml