We recorded an explanatory video for this Demo: 📺 bilibili.
What is DeepResearch?
Deep Research (also known as Agentic Deep Research) refers to an intelligent research agent where a Large Language Model (LLM) collaborates with tools (such as search, browser, code execution, memory storage, etc.) to complete complex research tasks in a closed loop of “multi-turn reasoning → retrieval → verification → fusion”. Different from single-retrieval RAG (Retrieval-Augmented Generation), Deep Research is more like a human expert’s approach — first making a plan, then constantly exploring, adjusting direction, verifying information, and finally outputting a well-structured and sourced report.Prerequisites
In this development, we will complete the example based on the UltraRAG framework. Considering that most users may not have computing servers, we will implement the entire process on a MacBook Air (M2) to ensure the environment is lightweight and easy to reproduce.API Preparation
- Retrieval API: We use Tavily Web Search. You can get 1000 free calls upon initial registration.
- LLM API: You can choose any large model service according to your habits. In this tutorial, we use gpt-5-nano as an example.
API Settings
We provide two ways to pass the API Key: environment variables and explicit parameters. Environment variables are recommended as they are safer and avoid API Key leakage in logs. In the UltraRAG root directory, rename the template file.env.dev to .env, and fill in your key information, for example:
Pipeline Introduction
In this example, we will implement a lightweight Deep Research Pipeline. It has the following basic functions:- Plan Formulation: The model first formulates a solution plan based on the user’s question;
- Sub-question Generation and Retrieval: Decompose big questions into retrievable sub-questions and call Web search tools to obtain relevant information;
- Report Organization and Filling: Gradually improve the content of the research report;
- Reasoning and Final Generation: After the report is completed, the model gives the final answer.
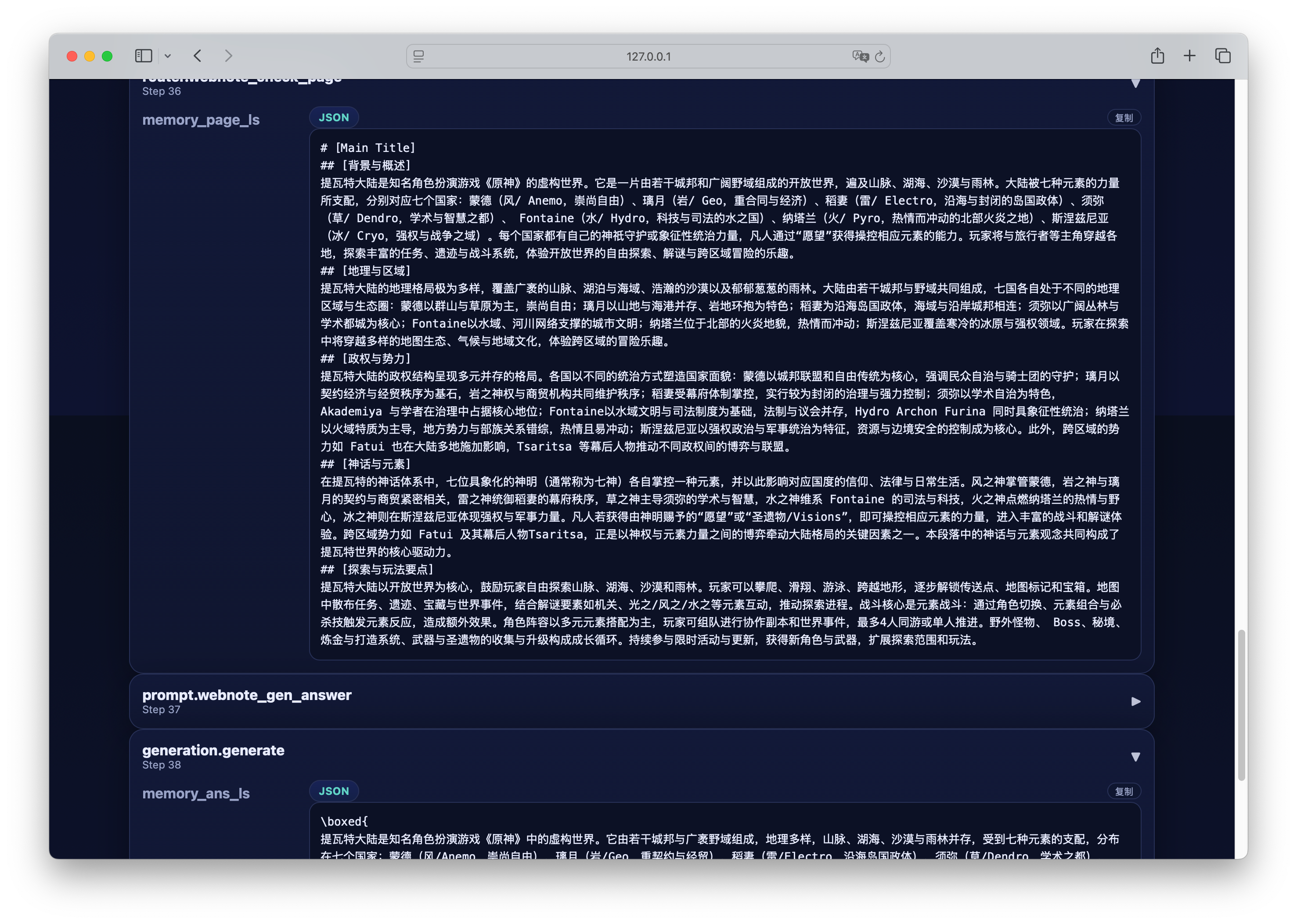
- Initialization Phase: The model generates a plan based on the user’s question and constructs an initial report page accordingly.
- Iterative Filling Phase:
- The system checks if the current report page is fully filled.
- The criterion is: whether the string “to be filled” still exists in the page.
- If the report is not yet complete, the model generates a new sub-question combining the user’s question, plan, and current page, and triggers Web retrieval.
- The retrieved documents are used to update the page, then entering the next round of checking.
- This process iterates until the page is filled.
examples/webnote_websearch.yaml

Run
Construct Question Data
First, create a new file namedsample_light_ds.jsonl under the data folder and write the questions you want to research. For example:
data/sample_light_ds.jsonl

Construct Parameter Configuration File
Execute the following command to generate the parameter file corresponding to the pipeline:examples/parameter/webnote_websearch_parameter.yaml
Start
Before running, don’t forget to set your API Key: