UltraRAG Development Practice
Server Alias Reuse-based RAG Workflow
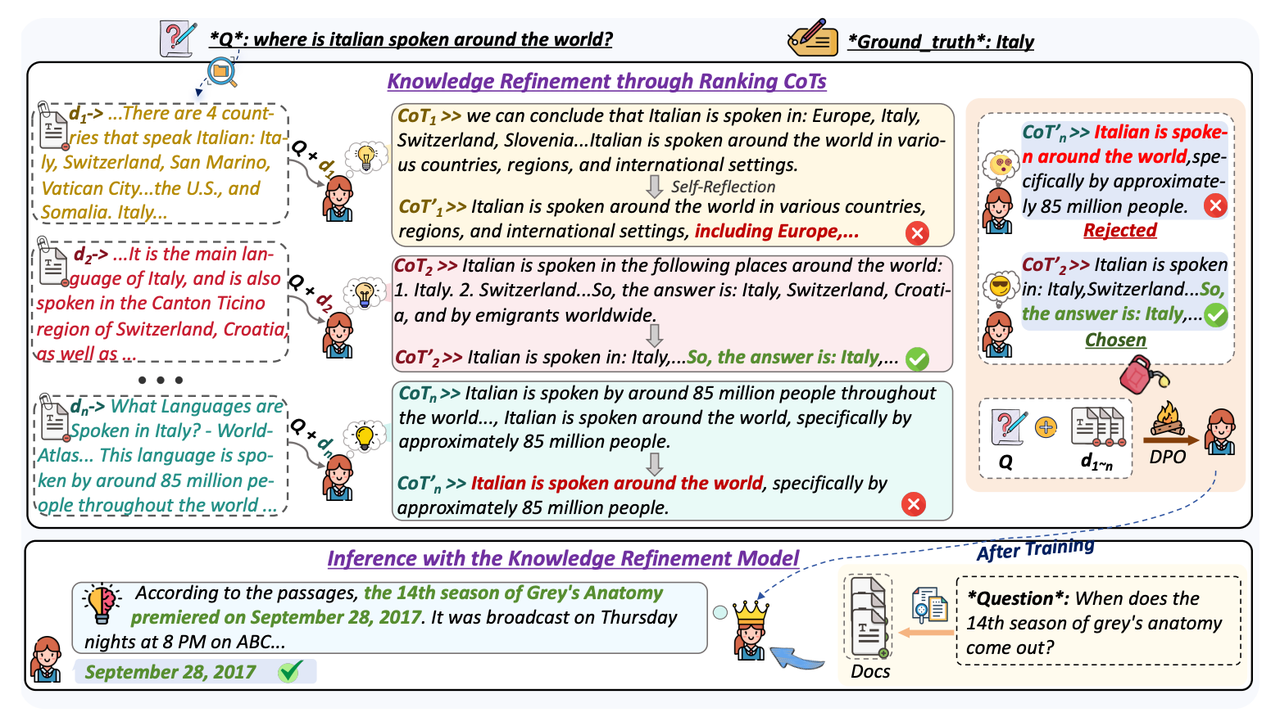
This section implements a RAG workflow that requires reusing the Generation Server — RankCoT (Knowledge Refinement + Final Answer).

 examples/RankCoT.yaml
Here we alias the same
Open examples/parameter/RankCoT_parameter.yaml
You can see that
examples/RankCoT.yaml
Here we alias the same
Open examples/parameter/RankCoT_parameter.yaml
You can see that
Paper: https://arxiv.org/abs/2502.17888RankCoT consists of two stages: first, a “knowledge refinement model” refines the retrieved documents, then an “answer generation model” generates answers based on the refined results. Both are essentially LLM inferences, so in UR-2.0, the same Generation Server code can be reused through Server aliases, only assigning different aliases and configuring different parameters/models in the Pipeline (see Server Alias Reuse Mechanism for details).
Step 1: Clarify Workflow Structure
Let’s first review the original RankCoT workflow structure diagram proposed in the paper:Step 2: Implement Necessary Tools
The knowledge refinement part of RankCoT first generates a reasoning chain based on the retrieved external knowledge and the question. For this, add the following code inservers/prompt/src/prompt.py:
servers/prompt/src/prompt.py
servers/prompt/src/prompt.py:
servers/prompt/src/prompt.py
Step 3: Write Pipeline Configuration File
Create a new YAML file under theexamples/ directory, such as RankCoT.yaml:
examples/RankCoT.yamlservers/generation as cot and gen, and call them separately in the Pipeline.
Step 4: Configure Pipeline Parameters
Run the following command:examples/parameter/RankCoT_parameter.yaml, and assign different models or inference parameters for the two aliases:
examples/parameter/RankCoT_parameter.yamlcot and gen each have independent parameter blocks without overwriting each other.