UltraRAG Development Practice
Loop-based RAG Workflow
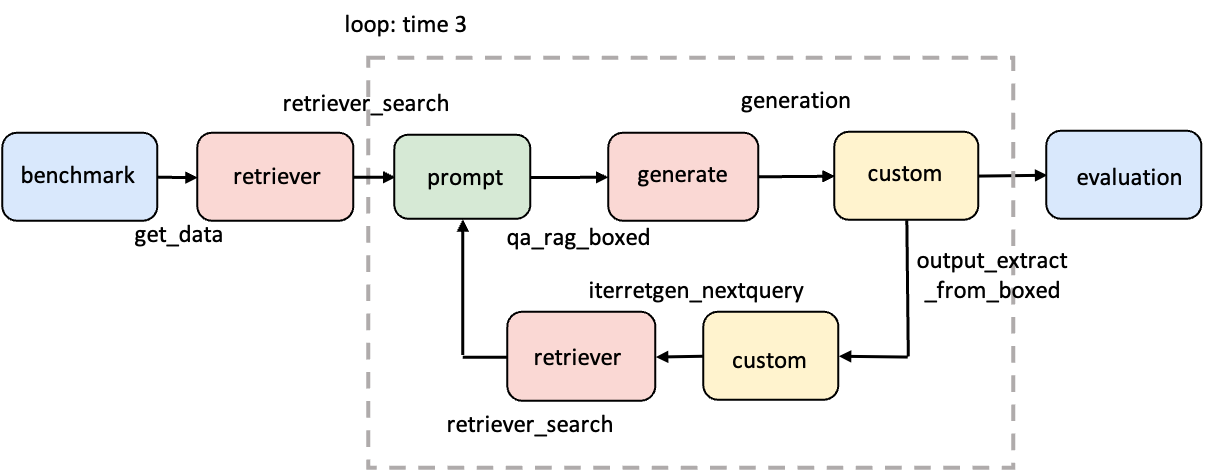
This section will guide you to implement a typical iterative reasoning RAG workflow: IterRetGen. This process supports repeatedly updating queries based on model outputs, gradually converging to better answers.

 examples/IterRetGen.yaml
Open the generated examples/parameter/IterRetGen_parameter.yaml
examples/IterRetGen.yaml
Open the generated examples/parameter/IterRetGen_parameter.yaml
Paper: https://arxiv.org/pdf/2305.15294
Step 1: Clarify the Workflow Structure
Let’s first review the original workflow diagram of IterRetGen proposed in the paper:- The answer generated by the model in each round is concatenated with the original question as the query for the next round of retrieval.
- This process is executed N times according to the set maximum number of loops.
- Except for the prompt and custom modules that need to be implemented by yourself, other functions can be directly reused from UltraRAG built-in tools.
Step 2: Implement the Necessary Tool
IterRetGen concatenates the query and the answer generated in the current round as the query for this round. To do this, add the following code inservers/custom/src/custom.py:
servers/custom/src/custom.py
Step 3: Write the Pipeline Configuration File
Create a new YAML file under theexamples/ directory, such as IterRetGen.yaml:
examples/IterRetGen.yamlStep 4: Configure Pipeline Parameters
Run the following command:examples/parameter/IterRetGen_parameter.yaml and modify the configuration as follows:
examples/parameter/IterRetGen_parameter.yaml