Documentation Index
Fetch the complete documentation index at: https://ultrarag.openbmb.cn/llms.txt
Use this file to discover all available pages before exploring further.
UltraRAG
UltraRAG 是首个基于 Model Context Protocol (MCP) 架构设计的轻量级 RAG 开发框架,专为科研探索与工业原型设计打造。它将 RAG 中的核心组件(如 Retriever、Generation 等)标准化封装为独立的 MCP Server,实现了基于函数级 Tool 接口的灵活扩展。配合 MCP Client 的流程调度能力,开发者能够通过 YAML 配置实现对复杂控制结构(如条件、循环等)的精确编排。此外,系统支持算法逻辑向对话演示界面的无缝迁移,极大地优化了复杂 RAG 系统的开发全链路效率。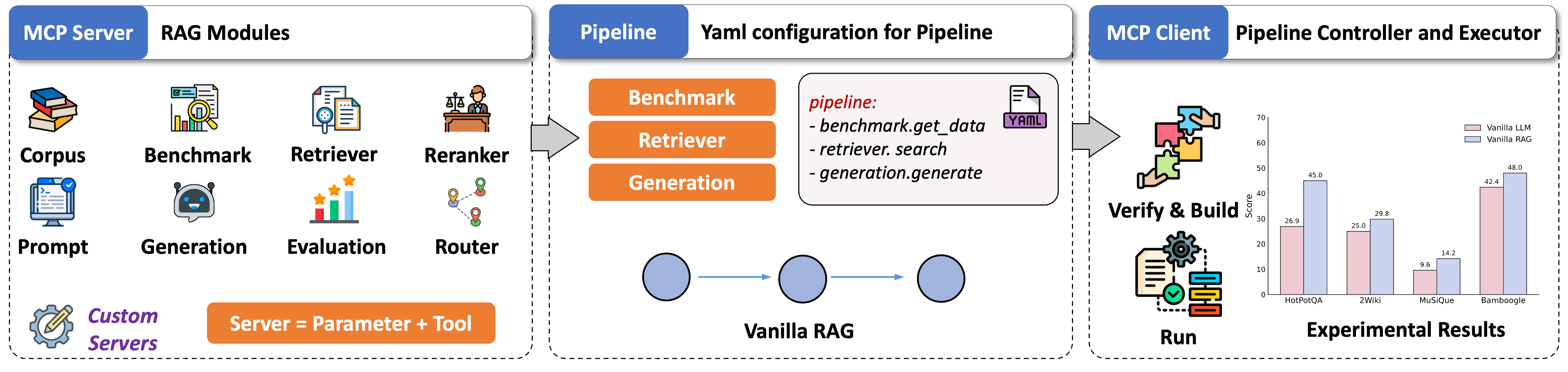
📑 Pipeline · 流程定义
核心蓝图:用户通过 YAML 编写的任务逻辑,定义了各组件的执行顺序与业务逻辑,实现推理流程的配置化。
🕹️ Client · 调度中枢
指挥中枢:负责解析 Pipeline 配置,统一协调各 Server 间工具的调用与数据传递,确保流程精准执行。
⚙️ Server · 功能执行
能力载体:将核心功能标准化封装为独立服务,支持通过简单接口实现新模块的快速扩展与灵活组合。
🖥️ UI · 交互演示
视觉门户:将 YAML 定义的逻辑一键转化为直观的对话界面,显著提升了系统的调试效率与演示效果。
Why UltraRAG?
RAG 系统正经历从静态链式串联向自主推理体系的范式演进,愈发依赖模型的主动推理、动态检索与条件决策。然而,传统框架在应对多轮交互与动态更新时,往往面临灵活性不足、模块深度耦合、结构松散等瓶颈,导致研究者难以高效复现与横向对比。 UltraRAG 旨在打破这一僵局,为开发者提供一套标准化、解耦且极简的开发新范式:🚀 低代码编排复杂流程
推理编排:原生支持串行、循环与条件分支等控制结构。开发者仅需编写 YAML 配置文件,即可在数十行代码内实现复杂的迭代式 RAG 逻辑。
⚡ 模块化扩展与复现
原子化 Server:基于 MCP 架构将功能解耦为独立 Server。新功能仅需以函数级 Tool 形式注册,即可无缝接入流程,实现极高的复用性。
📊 统一评测与基准对比
科研提效:内置标准化评测流程,开箱即用主流科研 Benchmark。通过统一指标管理与基线集成,大幅提升实验的可复现性与对比效率。
✨ 交互原型快速生成
一键交付:告别繁琐的 UI 开发。仅需一行命令,即可将 Pipeline 逻辑瞬间转化为可交互的对话式 Web UI,缩短从算法到演示的距离。