1. Pipeline Structure Overview
examples/LightResearch.yaml

2. Compile Pipeline File
Execute the following command to compile this complex workflow3. Configure Running Parameters
Modifyexamples/parameter/LightResearch_parameter.yaml.
examples/parameter/LightResearch_parameter.yaml
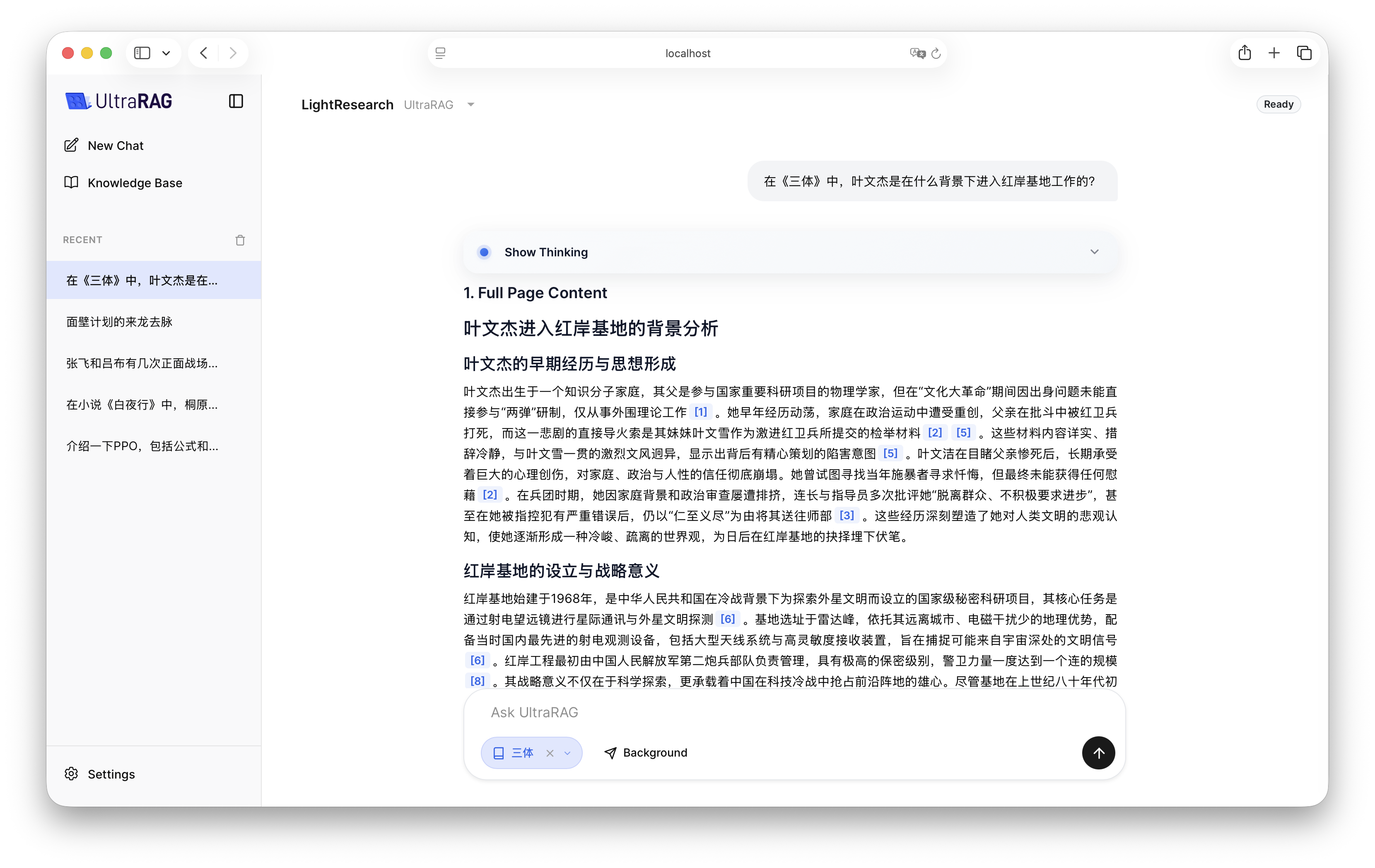
4. Effect Demonstration
After configuration is complete, start the LightResearch Pipeline in UltraRAG UI. Different from standard RAG, you will observe that the system goes through multiple rounds of autonomous thinking and retrieval processes before giving the final answer, finally generating a deep review with multi-level headings, detailed arguments, and accurate citations.