1. Pipeline Structure Overview
examples/LLM.yaml

2. Compile Pipeline File
Execute the following command in the terminal to compile:3. Configure Running Parameters
Modifyexamples/parameter/LLM_parameter.yaml according to your environment needs. The following example shows how to switch the backend from vLLM to OpenAI API standard interface and adjust the model name and system prompt.
examples/parameter/LLM_parameter.yaml
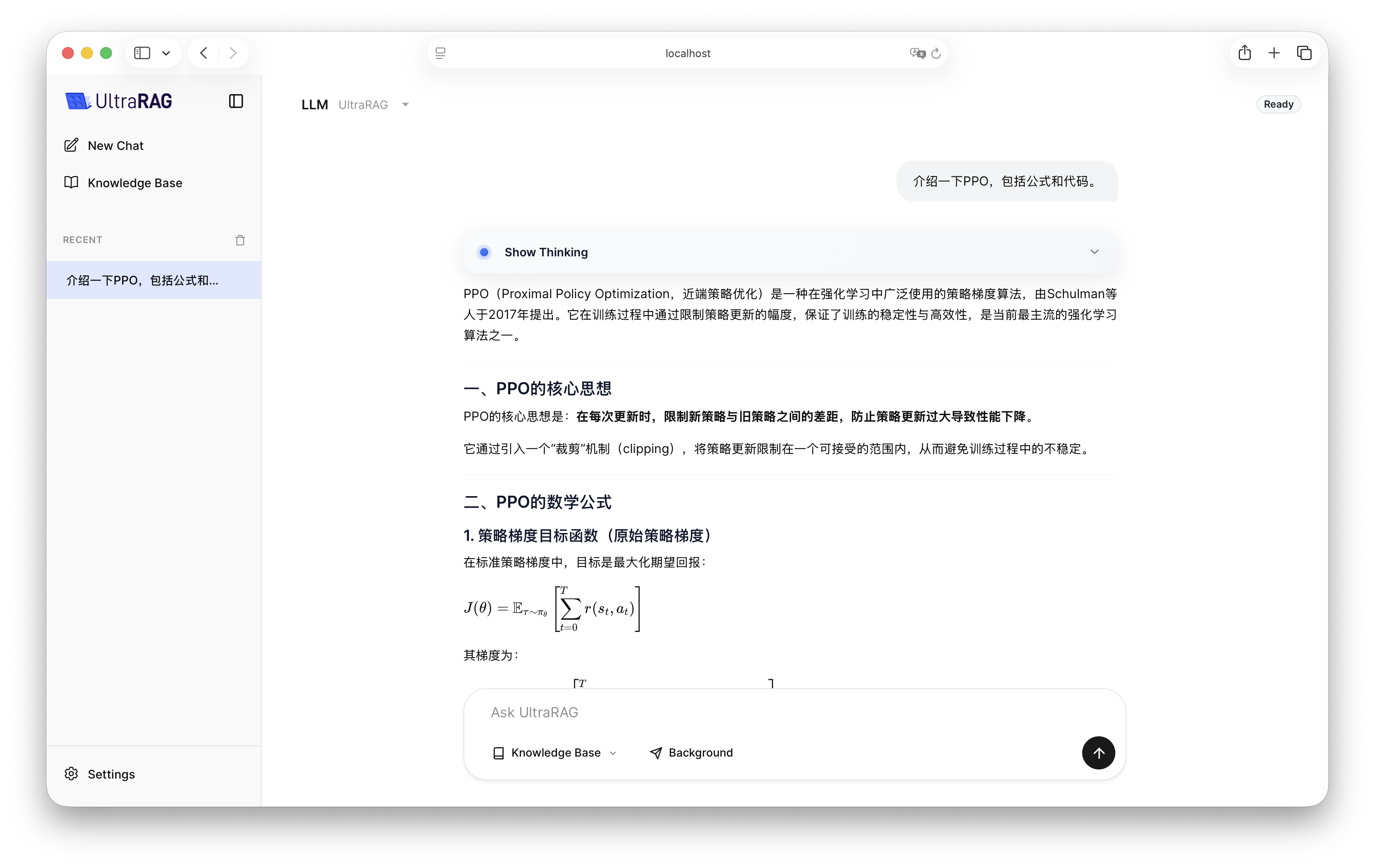
4. Effect Demonstration
After configuration is complete, start UltraRAG UI and select LLM Pipeline in the interface to start interaction.