1. Pipeline Structure Overview
examples/RAG.yaml

2. Compile Pipeline File
Execute the following command in the terminal to compile:3. Configure Running Parameters
Modifyexamples/parameter/RAG_parameter.yaml. In RAG scenarios, in addition to configuring the LLM generation backend, you also need to focus on configuring the Embedding retrieval backend.
examples/parameter/RAG_parameter.yaml
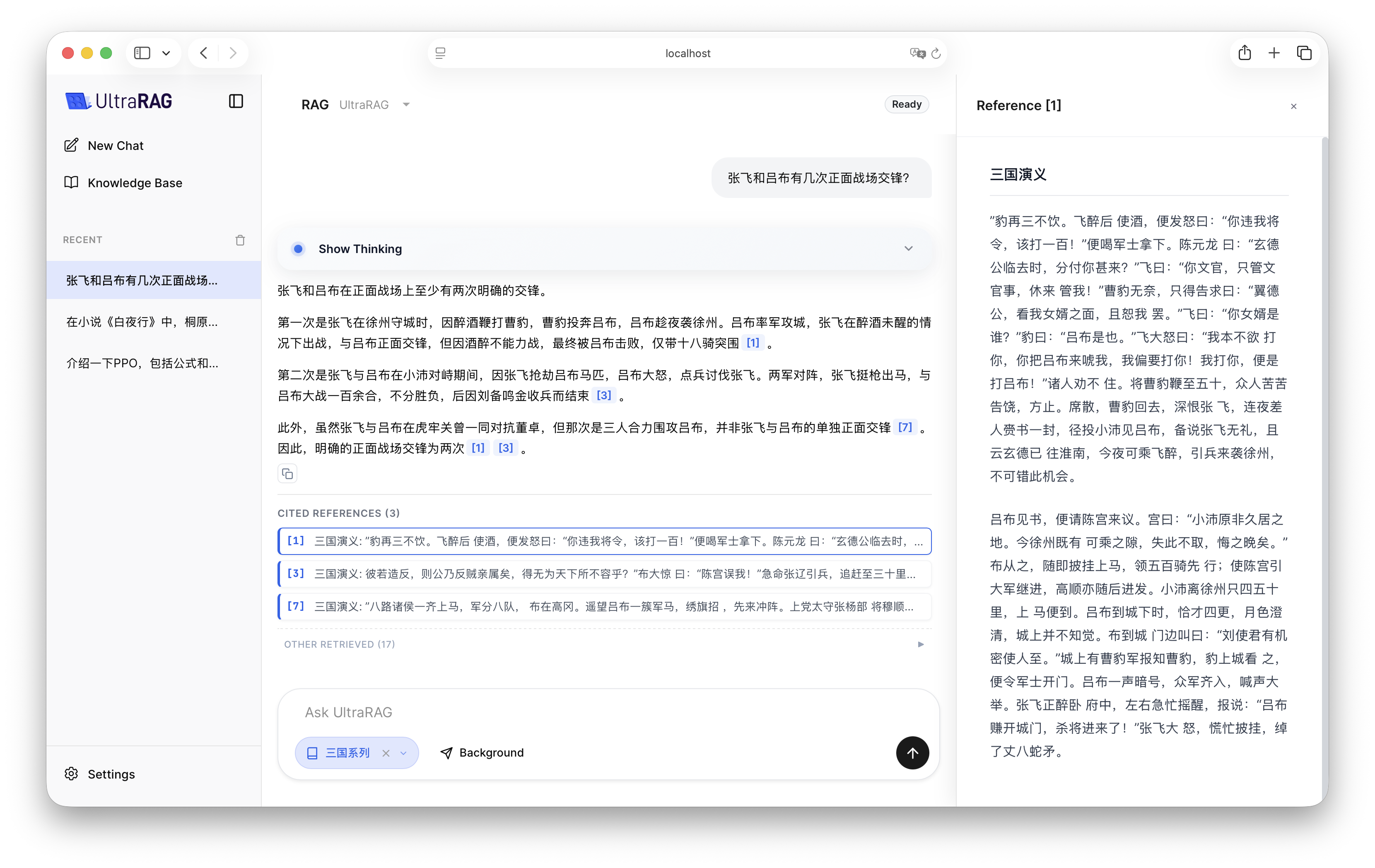
4. Effect Demonstration
After configuration is complete, start UltraRAG UI, select RAG Pipeline in the interface, and select the corresponding knowledge base. You will see how the LLM combines retrieved document fragments to give more accurate and cited answers.